Figure 1. Figure 2. Chronology of Dickens by most frequent words.
Rybicki, Jan Krzysztof
Uniwersytet Jagiellonski, Poland
jkrybicki@gmail.com
It all began so well. We noticed, at least since Mosteller and Wallace (1964), that authorship attribution problems could be solved by counting easily countable linguistic items, such as very frequent words, and applying combinations of statistical procedures that humanists can be more or less comfortable with. And we are now quite comfortable applying such combinations, for instance my favorite mix of Burrows’s Delta (Burrows 2002), cluster analysis and network analysis, to look for more than mere authorial signal in those nice ready-made chunks of data, novels: for signals of genre, gender, chronology, theme, translator. We also have the two American giants: Moretti and his Marxian evolutionary view of literature at the basis of his Distant Reading (2015), and Jockers and his Macroanalysis, which distant-reads by those countable features (2013). And we even have software that does it all from retrieving text to drawing pretty diagrams with (almost) a single mouse click, such as the stylo package (Eder et al., 2013) for R (R Core Team, 2014), and we can get even prettier graphs with network analysis tools such as Gephi (Bastian et al., 2009).
One of the most attractive but also the most controversial tenets of Jockers’s Macroanalysis goes like this:
The literary scholar of the twenty-first century can no longer be content with anecdotal evidence, with random “things” gathered from a few, even “representative,” texts. We must strive to understand these things we find interesting in the context of everything else, including a mass of possibly “uninteresting” texts (Jockers, 8).
No wonder that we stylometrists love this statement (while Harold Bloom is gnashing his teeth). What this means, says Jockers, is that we should verify traditional literary systematics by going beyond the canon (if it still exists) and apply the Big Data approach: create a new image of, say, Victorian literature, not on the basis of the several dozen usual “representative writers” such as Dickens and Thackeray and Trollope, but on the thousands of novels written more or less during Queen Victoria’s reign (but there is still the question of those that have not been preserved). Close reading is not enough, says Jockers. Get your computer and mine your data!
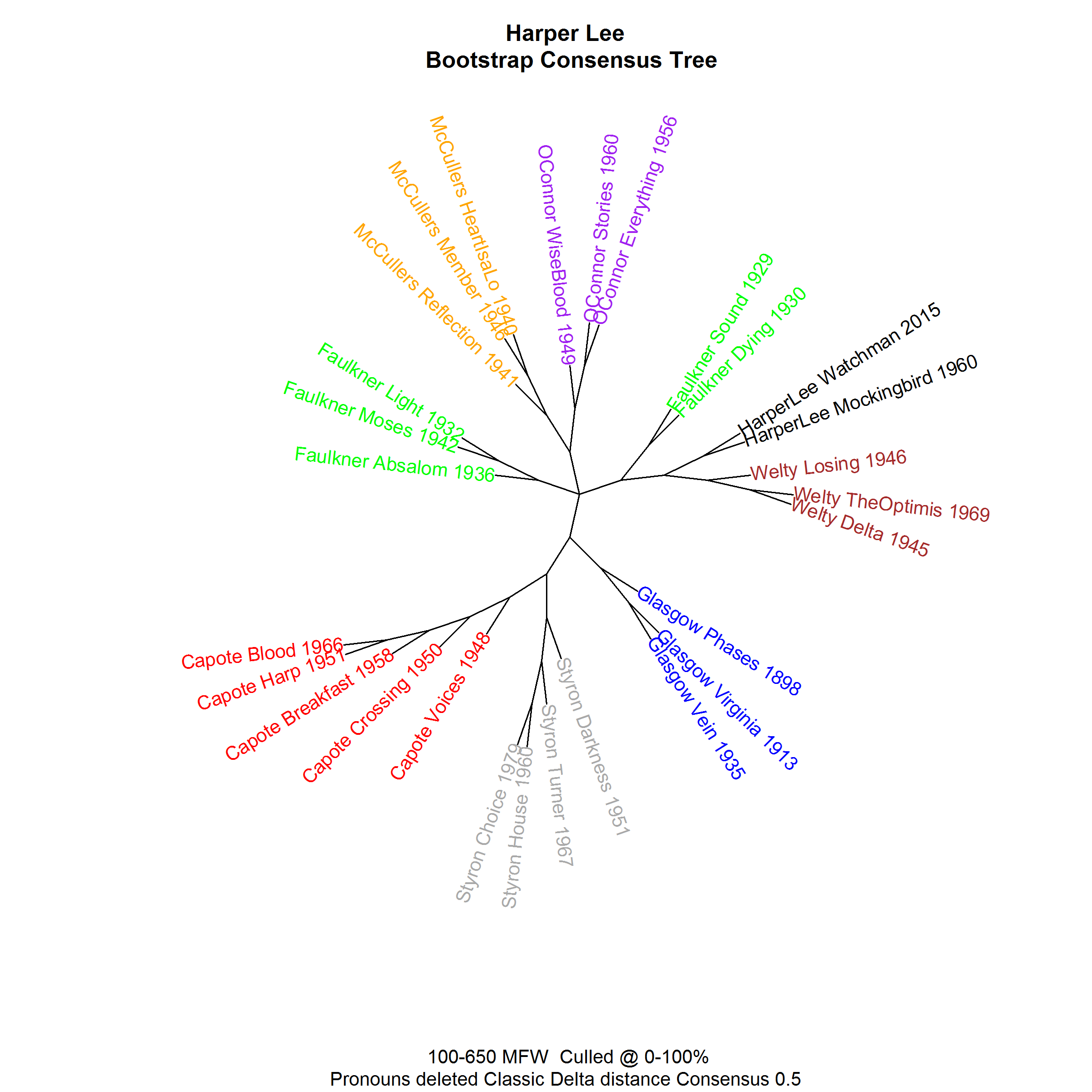
And that’s exactly what we do. We can show you pretty and colorful tree diagrams or networks, and they seem to be growing bigger every year. Don’t get me wrong: I am still very proud of how this cluster analysis tree (Fig. 1) shows that Harper Lee did indeed write Go Set A Watchman as well as To Kill A Mockingbird (there goes one conspiracy theory), even if it seems to produce two different Faulkners…
[Figure 1]
…or of how this network analysis (Fig. 2) corroborates the traditional division of Dickens’s oeuvre into stages early (green), second (yellow), mature (red) and late (purple); or even how it suggest a slightly different classification of some borderline cases…
[Figure 2]
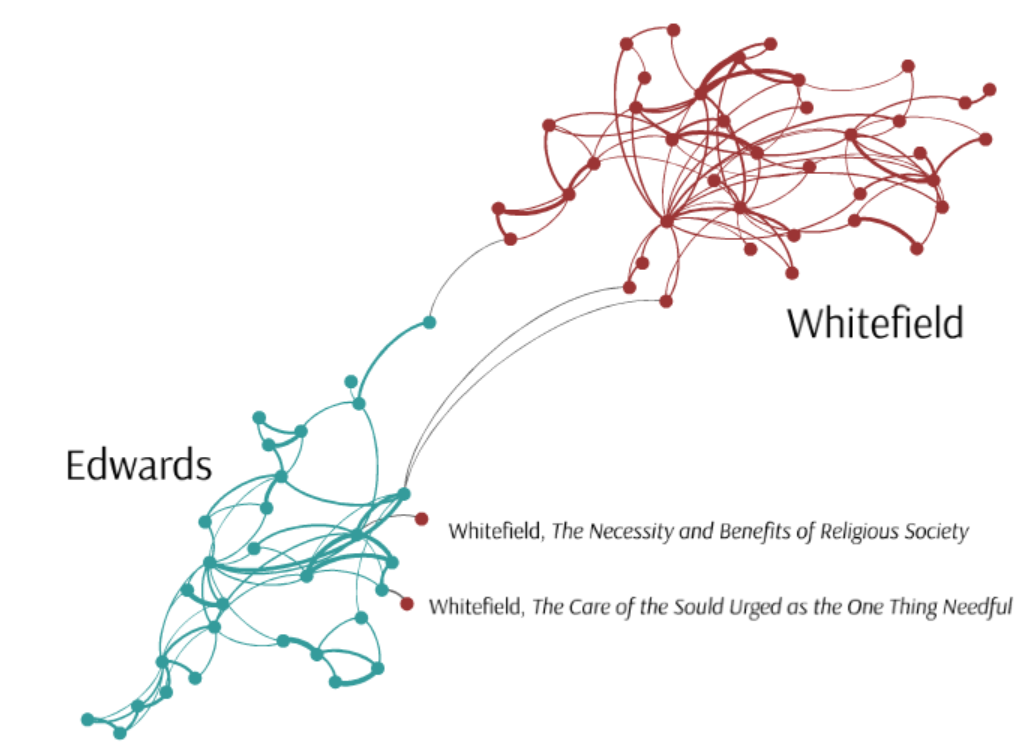
…or even when some irregularities cannot be readily explained, such as this misattribution of two sermons by Whitefield when compared with the work of an even more famous Great Puritan Awakening preacher, Jonathan Edwards (Fig.3):
[Figure 3]
It is when our corpora and networks grow beyond a certain point that problems may be starting. A thousand-novel network analysis of English literature exhibits a nice chronological succession, very Morettian, but it already takes some fancy zooming in and out to take in both the general image and the position of individual writers and works (Fig. 4).
[Figure 4]
Don’t get me wrong: when it is just the big picture that we want, it all makes sense. The next network diagram (Fig. 5) shows 1000 Polish novels (white), 600 Polish translations from English (red) and 400 Polish translations from other languages (other colors). This visualization provides good evidence for the existence of translationese, and different versions of translationese at that: observe how the translated texts seem to be shift away from the Polish originals, and how some of the Polish translations tend to cluster by original language. But this visualization also makes it all but impossible to search for individual novels in this spider’s web.
[Figure 5]
Distant reading threatens to lose any possibility of being reunited and combined with close reading when the corpora we analyze become Big Data, or at least a literary/humanist version of Big Data. The next network diagram presents a most-frequent-word usage analysis of 9000 novels in English, colored by chronology (Figure 6). It seems to suggest that while 18 th- and 19 th-century literature (going by half-centuries, dark blue, light blue, purple, red) tended to observe a certain chronological evolution, but then the 20 th and the 21 st century are nothing but a Big Bang of white light. Which may be a nice metaphor, but has little to do with reading, close or distant for that matter.
[Figure 6]
Stylometry has been called by Willard McCarty “the great exception to the stalemate” of digital humanites “because it has produced ‘mounting evidence,’ as Burrows says, that literature is probabilistic – hence that the most elusive of cultural qualities behaves in the same way as the natural world (McCarty 2013, 14). But, unless we find new ways of marrying distant with close, of reading our Big (or Biggish) Data, it might find itself in a stalemate too.